Markets as a Judge: Scaling Human Preference Data with Prediction Markets
— AI, Machine Learning, RLHF, Prediction Markets, Human Feedback — 5 min read
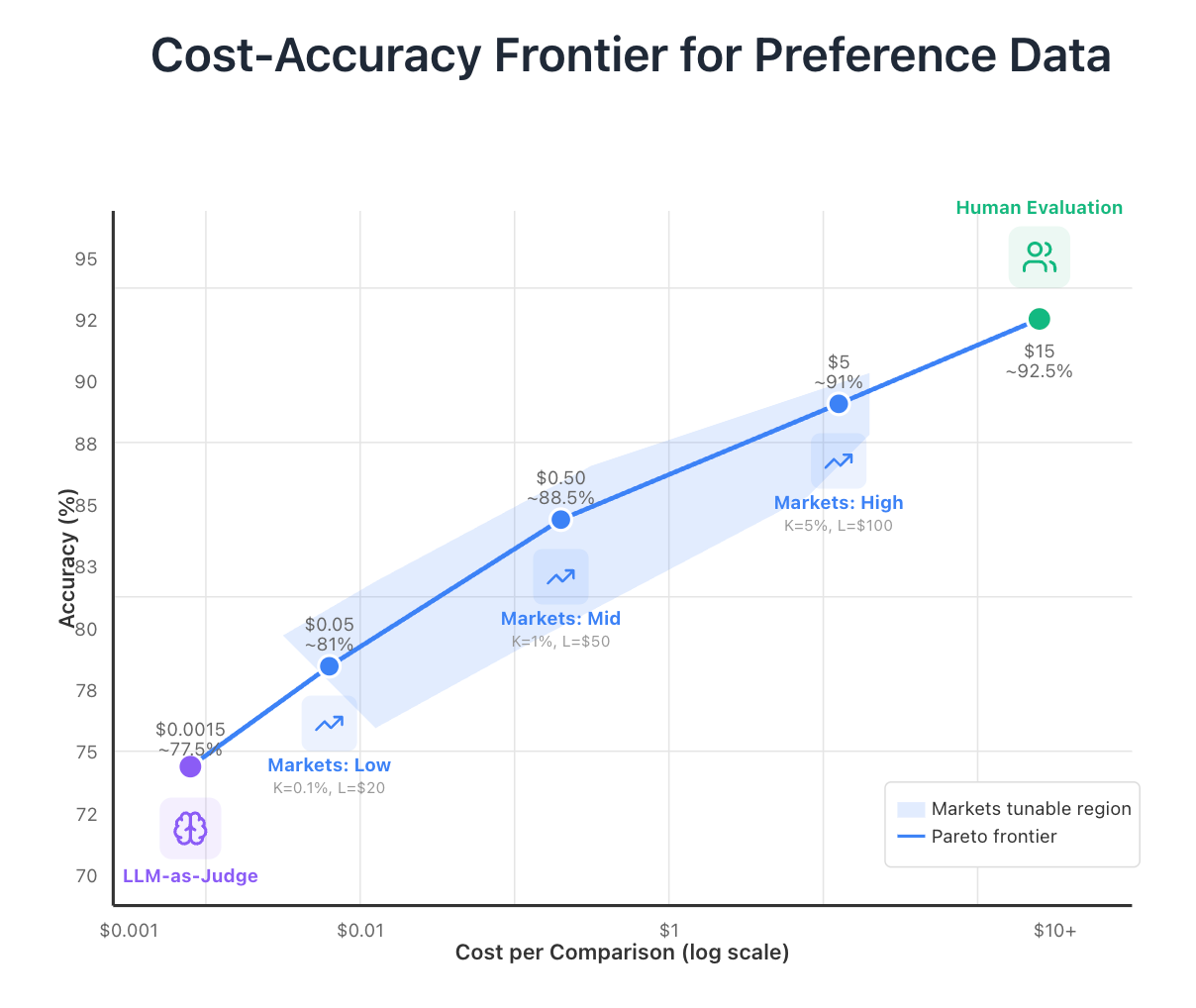
Training language models on human preferences is expensive. The RLHF and DPO paradigms demand large volumes of preference data — pairs of completions where a human judge says which response is better — and today's options for generating that data sit at two extremes with almost nothing in between.
LLM-as-a-judge systems (using GPT-4o, Claude, etc.) cost roughly $0.001 per comparison and achieve 70–85% accuracy against human consensus. But they have well-documented biases: they favor verbose responses, markdown formatting, bullet points, and style over substance. Training on LLM-judged preferences risks baking those biases into your model.
Expert human judges deliver 90–95% accuracy at $5–15 per comparison once you factor in multiple raters and quality assurance. That's a big improvement in quality but at a enourmous 1,000–15,000× cost gap.
The space between these extremes is almost entirely empty, yet it's exactly where many use cases live. You often don't need gold-standard human evaluation for every comparison, but LLM judges aren't good enough. What if you could target any point on the cost-accuracy frontier by turning two knobs?
Prediction Markets Can Fill the Gap
My idea is to use prediction markets as judges. For each preference pair — a prompt and two completions — create a market with two outcome tokens: Token A (completion A wins) and Token B (completion B wins). Traders arrive, evaluate the pairs using whatever methods they choose, and trade based on their predictions. The market price on Token A is your preference signal: a price of $0.80 means the market thinks completion A wins with 80% probability.
Markets are good at aggregating distributed information. Individual traders might use LLMs, manual review, specialized evaluation tools, or domain expertise — the market doesn't care how they form their predictions, only that they put capital behind them. That diversity of methods helps cancel out the systematic biases that plague any single evaluation approach. And unlike LLM ensembles, markets create skin-in-the-game incentives: a trader who discovers that a particular LLM judge is systematically wrong can profit by trading against it.
This is already valuable. But the market price signal is still just an approximation — at some point you need ground truth. And if you have to pay for human evaluation on every pair, you're back to the original cost problem. The trick is what happens next.
Only a Random Sample of Markets Actually Resolve
When trading closes, only K markets — selected at random — are actually evaluated by human judges. In those K markets, tokens for the winning completion pay out $1; tokens for the loser pay $0. In the remaining N − K markets, all tokens expire worthless.
This stochastic resolution is what makes the economics work. The market sponsor provides liquidity to all N markets, but most of that liquidity is virtual — it exists in tokens that will never resolve. Only the K evaluated markets generate real payouts. Yet traders must predict accurately across all markets because they don't know which ones will be judged. The result: you get informed price signals on all N pairs while only paying for K human evaluations.
The Numbers Are Kind of Absurd
Traditional human evaluation of 10,000 preference pairs at $15 each (three raters at $5) costs $150,000.
With markets-as-a-judge, total cost is K × (C_human + L), where L is the liquidity provided per market. Set K = 100 (a 1% sampling rate) and L = $10 in liquidity per market, and total cost drops to 100 × ($15 + $10) = $2,500. That's a 98.3% cost reduction.
The savings come from the fact that liquidity losses scale with K, not N. You're seeding all 10,000 markets with tokens, but only 100 of them ever pay out. The other 9,900 markets' liquidity was never real money at risk — it was virtual exposure that expired.
Two Knobs Let You Target Any Point on the Frontier
The defining feature of markets-as-a-judge is that you can tune it. Two knobs — sampling rate K and liquidity per market L — let you target any point on the cost-accuracy frontier.
At the low end (K at 0.1%, L at $10–20), you're paying roughly $0.01–0.10 per comparison. Traders are making quick judgments, probably running their own LLM evaluations with better prompting. Accuracy might reach 75–87% — a modest improvement over pure LLM-as-judge.
At intermediate settings (K at 1–2%, L at $10–100), costs land around $0.10–2.00 per comparison. Now the economics support traders investing real effort — running batteries of tests, manually reviewing outputs, building specialized evaluation tools. This is where I think markets' comparative advantage likely lives. Accuracy in this regime might reach 85–92%.
At the high end (K at 5–10%, L at $100–500), costs approach $5–10 per comparison, competitive with direct human evaluation. Here the market functions as a coordination mechanism for human evaluators, with the bonus that the non-evaluated pairs still carry informative price signals.
Where LLM-as-a-judge and human evaluation are fixed points on the frontier, markets let you optimize for specific budget and accuracy constraints.
I'll be honest: I don't know exactly where the accuracy lands at each regime. The relationship between market parameters and accuracy needs empirical calibration. The choice of automated market maker (constant-product curves, logarithmic scoring rules, etc.) affects price discovery and trader participation in ways that need testing. K also can't be arbitrarily small — traders need enough evaluated markets to justify their evaluation costs, and risk-averse traders discount high-variance outcomes. Getting that balance right is an empirical question.
But the economic foundations seem sound to me. Markets efficiently aggregate distributed information, and when that information concerns human preferences, they can serve as a scalable approximation of human judgment. And honestly, the idea that you could run thousands of simultaneous prediction markets to cheaply train better AI seems like exactly the kind of slightly-bonkers thing that might actually work.