First Fine Tune
To follow along with this tutorial, check out Sudoku-First Evals.ipynb in the Sudoku Repo.
In the last article, we looked at how to evaluate models on 4x4 sudoku and get a baseline for model performance. Now, lets fine-tune a model to improve performance.
First, let's discuss our goals with the fine-tuning. We want to build a dataset to improve GPT-3.5-turbo on the sudoku ‘brief_analysis’ task. There a lot of potential ways to create such a dataset. One way to do that would be to create a lot of examples of the task, and have humans write out answers to each example of the task. That approach might create high quality data, but would be expensive and time consuming. So, naturally, one might consider seeing if we can have language models themselves create training data.
In our previous article, we saw that gpt-4-turbo has a better score on the task than gpt-3.5-turbo on the task. What if we took examples from gpt-4-turbo and trained gpt-3.5-turbo on those examples? Presumably, this will result in an improvement on the task by gpt-3.5. This technique is called distillation, where we have a stronger model teach a task to a weaker model.
One problem is that gpt-4-turbo isn’t perfect at the task. As we saw, it gets the wrong answer 40% of the time. Since it doesn’t seem like it will improve gpt-3.5 on mistakes, we will filter those examples where gpt-4-turbo got the wrong answer. To get about 250 correct examples, we will perform 500 steps.
Here's the code to prepare the data samples:
samples = []
with get_openai_callback() as cb: for i in tqdm(range(500), desc='Processing'): solution = construct_puzzle_solution() _, _, history = pluck(deepcopy(solution)) puzzle = weighted_random_choice(history[1:]) prompt = brief_analysis.format(puzzle) message = model.invoke([ HumanMessage(content=prompt) ]) reasoning = message.content try: proposed = analysis_to_puzzle_solution(extraction_model, puzzle, reasoning) if is_proposed_solution_valid(puzzle, solution, proposed): #Let's create a data point samples.append((puzzle , solution, reasoning)) except: pass print(cb)qWe will save our samples insamples, naturally enough. Once again, we wrap our code in "get_openai_callback()" so that we can see the cost of this operation when completed.
Our main data loop will loop for 500 steps. We use get_openai_callback() to keep track of how much is spent creating this data. For 500 data points using gpt-4-1106-preview this will probably cost $3-$4. We start by creating a new random solution to puzzle with construct_puzzle_solution() and then get a “history ” which is an array include puzzles at various levels of solved from the solution to the hardest puzzle. We use weighted_random_choice() to select from the history array, where this function will choose from the list with a preference towards the harder puzzles.
Once we have a puzzle, we fill in the brief_analysis prompt, and then invoke the model to create reasoning for a solution to one cell of the puzzle. analysis_to_puzzle_solution() uses an extraction model (also gpt-4-turbo) to extract the updated cell and it’s value from the reasoning to create “proposed” a normalized update to the puzzle. We then check if the update is a valid solution, and if so, we add it to our samples array.
Our samples array should now contain several hundred examples. We now need to put them in a format for training using OpenAI’s fine-tuning service.
GPT-3.5 uses OpenAI’s chat format which is a turn-based format that assumes a back and forth conversation between a “user” participant and “assistant” participant. A chat training example is a dictionary including “messages” provided as a list of sides to the conversation. Each side of the conversation specifies the role (user or assistant) and the content of the user or assistant’s side of the chat. Each training example is provided as a json string.
Here’s the code to write the samples to a file:
solved_cell_json = []
for x in samples : user_message = brief_analysis.format(x[0]) messages_dict = { 'messages': [ {'role': 'user', 'content': user_message}, {'role': 'assistant', 'content': x[2]} ] } json_string = json.dumps(messages_dict) solved_cell_json.append(json_string)
# Writing to filewith open('./data/gpt-4-turbo-distilled-500.jsonl', 'w') as file: for message in solved_cell_json: file.write(message + '\n')Now that we have a JSONL file, we can upload it to OpenAI and start training. We navigate to https://platform.openai.com/finetune and click “+ Create”.
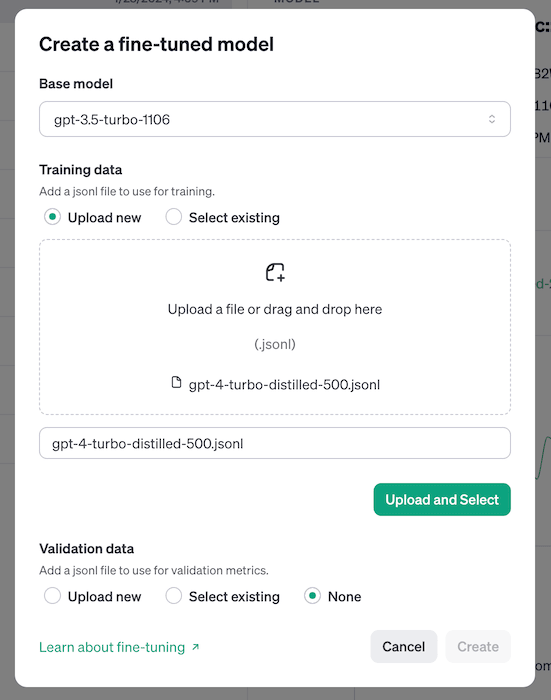
Using the fine-tuning interface we can select the “Base Model” as "gpt-3.5-turbo-1106" and the choose the file for uploading.
Once the file is chosen, click “Create” to kick off the fine-tuning process. It’s a really easy process. You can follow along with the training in their interface.
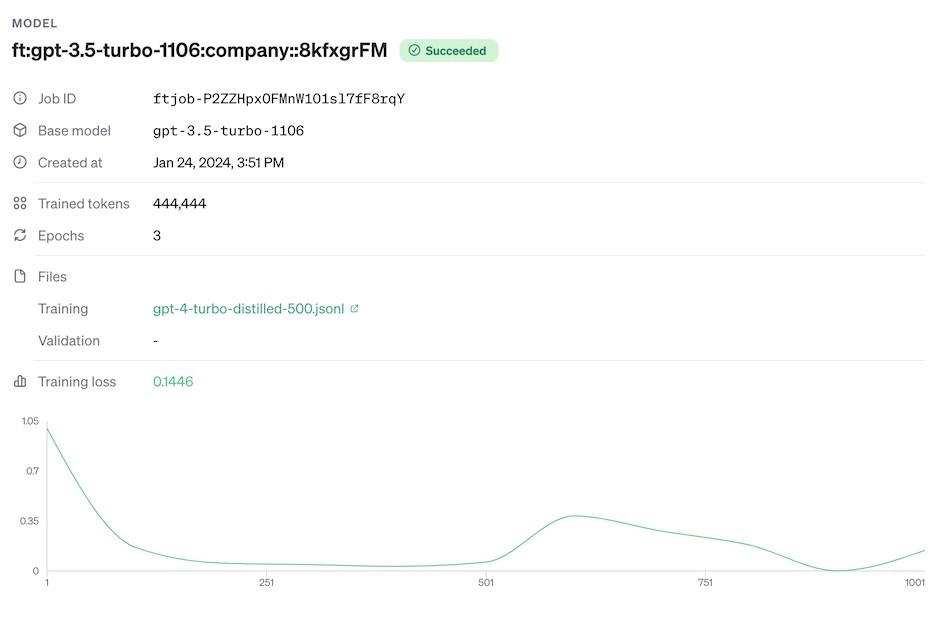
Now that we have a model, let's give it and name and test it. To make the models more memorable, I will use codenames using combined emojis (play around with these at Emoji Kitchen). I described emoji code names in this article. Let's call our new model:

We use the exact same test code that we used for gpt-3.5 and gpt-4-turbo. Below we've reproduced the results of the models evaluation.
tired face cupcake ⦁ 80 out of 100 correct
Click on an example to see details here.
And, indeed, comparing with GPT-3.5-turbo and GPT-4-turbo we see a big improvement!
| Model | Accuracy |
|---|---|
tired face cupcake | 80/100 |
| gpt-4-1106-preview | 65/100 |
| gpt-3.5-turbo-1106 | 50/100 |
Conclusion
We've looked at how to fine-tune models on 4x4 sudoku, and shown how it exceeds our baseline.