Deep Funding Jurors Need Tools
— Deep Funding, Open Source, AI — 11 min read
The Ethereum ecosystem runs on roughly 50 core software projects used by millions worldwide. How much value does each provide to the network?
A group of eminent community members from across Ethereum has been assembling to answer this question through a project called Deep Funding. They're presented with pairs of projects and asked simply: "Which has been more valuable to Ethereum's success?" When one is chosen, they specify how many times more valuable it is.
Deep in this data, I found something that reveals the challenge they face: Juror 17 rated Solidity 999x more valuable than Remix.
Maybe that's reasonable—Solidity is the dominant smart contract language while Remix is just one IDE among many. But here's what that extreme comparison actually does: when I computed the implied funding from all the data received so far, Solidity gets 24.56% of total allocation. The 999x multiplier pulls hard in that direction—when I rerun the optimization with just that one number changed to 50x, Solidity's share drops to 19.23%. One extreme comparison among hundreds creates a five percentage point swing, representing potentially millions of dollars in funding if this approach were to be adopted across open source funding.
I don't mean to question Juror 17's judgment. They were asked a seemingly simple question and gave an honest answer. The problem is that neither they nor any other juror could see how their "999x" would ripple through the entire system. Deep Funding asks for local comparisons but generates global allocations, and jurors can't see the bridge between the two.
At least, not yet.
Deep Funding's Elegant Theory
Deep Funding is an innovative and bold vision for improving the funding of open source projects. You can read Vitalik's original tweet on it here.
Ethereum was built through public support of open source software. Across all funding mechanisms, the Ethereum ecosystem is likely spending hundreds of millions of dollars in open source funding. For a long time, the primary source of funding for many open source projects has been ad hoc charitable donations. More recently, the crypto landscape has innovated some more systematic approaches: Gitcoin Grants, Optimism Retro PGF, Uniswap Grants, among others.
But these mechanisms are still a substantial investment of time and effort for funders who may just want their dollars to support a whole ecosystem that they care about. For example, an Ethereum supporter might ask: why can't I just donate to all Ethereum projects in proportion to their value to the ecosystem?
Deep Funding tackles this desire head on. In one round, we take all available funding and divide it across all meritorious open source projects in proportion to their value to the ecosystem. In fact, we go further, treating each project as its own ecosystem and dividing funding between an open source project and its open source dependencies. In one fell swoop, each dollar of funding can potentially support thousands of open source projects.
But how can we actually allocate funding in a way that donors can trust? The natural thing to do is to have those eminent community members directly rank every project. But that hits an immediate wall. Even the most dedicated experts don't have the time or ability to make the huge number of decisions necessary to allocate funding across thousands of projects.
To solve this problem, Deep Funding uses three techniques: decomposition of the problem, comparative judgement, and distilled human judgement. Decomposition is the process of taking a nearly impossible problem like "What fraction of total value to Ethereum is provided by each of the following projects: [massive list of one thousand projects]?" and breaking it down into smaller, more manageable pieces. Comparative judgments is the use of comparing small number of items, usually two, at a time.
Decomposition and comparative judgments can be combined to break down "What fraction of total value to Ethereum is provided by each of the following projects: [massive list of one thousand projects]?" into a series of easier questions like "Between projects A and B, which project is more valuable to Ethereum and by how much?"
Distilled human judgment is the use of AI to make decisions on behalf of trusted people. After we've decomposed the problem into simple comparative judgements, we can have community members act as "jurors" who evaluate a small subset of the possible comparisons. We then train AI on juror judgements, essentially distilling their preferences, and making it possible to scale their decision-making across all comparisons needed to fully solve the problem.
Deep Funding as an idea is deeply elegant. If it works, we can take a nearly impossible task (ranking potentially thousands of projects) and decompose it into a relatively small number of simple comparisons that experts can make. Beautiful.
But does it actually work?
The Messy Reality: What the Data Reveals
To test Deep Funding in practice, the deep funding team is running a series of contests. The first contest is currently active. Contestants are asked to build AI models that satisfy the preferences of jurors. A jury was assembled of some of the top web3 developers, auditors, open-source maintainers, and passionate community members (see the juror list here).
For this first round, jurors collectively reviewed 45 open source projects that contribute to the Ethereum ecosystem. Jurors were asked to compare pairs of projects with each pair being randomly selected from the 45 open source projects being considered. For each pair, jurors were asked: "Which [project] has been more valuable to the success of Ethereum?" The jurors would then pick the more valuable project and provide a multiplier that represented how much more value the winning project was over the less valuable project. The juror was also asked to explain their reasoning for the choice and multiplier value.
As part of the contest, a third of the juror comparisons have been released. And they reveal three critical challenges that suggest the current approach isn't working as intended.
Challenge 1: The Task Is Harder Than Expected
There are about 70 juror members. For this contest, they contributed only 550 comparisons over 9 months. That’s around 8 comparisons per juror, or roughly 2 comparisons per day across all jurors, a paltry amount. Note that this is not a criticism of the jurors—who I commend for taking time out of their busy schedules to take part in this very experimental initiative. Rather, I believe this is an indication of how challenging this task is for even extraordinarily talented people. No one involved had ever done this task before, there is no training for it, and no tools to help (yet!).
Challenge 2: Jurors Can't Agree on Basic Ordering
Looking at the comparisons, there was disagreement 40% of the time about which project should be ranked higher. This may represent genuine disagreement about value, but I think it is equally likely to represent that this is a challenging task when first presented. It may suggest that individual jurors might not be applying well-developed preferences and that if they were to do the task again might arrive at a different answer. It may be that the value is somewhat ambiguous, especially if you haven't deeply dove into the data around the projects.
Challenge 3: Multipliers Are All Over the Map
In terms of the multipliers given by different jurors, they vary wildly. Some are providing a median multiplier of 4, while others are providing multipliers of 200-1000. This suggests radically different views about the value of projects—or a lack of a good baseline around what is reasonable to provide good heuristics for the jurors.
This brings us back to Juror 17. Their 999x multiplier might have been intended, but did they understand it would translate to 25% of all funding going to Solidity? Is this really a good way to potentially distribute hundreds of millions of dollars of Ethereum ecosystem funding?
Without tools to show jurors the implications of their choices, they're flying blind.
Tools Can Bridge Theory and Practice
Instead of expecting jurors to magically produce consistent comparisons, we can give them tools to help them translate their intuitions into coherent preferences. Without tools, jurors are guessing. With them, they can learn what works, see what their choices actually do, and adjust until the outcomes match their intentions.
The connection is straightforward:
- If tools can make it easier to do comparisons, then more comparisons can be made faster
- If tools can help jurors be more consistent and methodical in their comparisons, then it may lower disagreement and ensure rankings that better reflect preferences
- If tools can help jurors understand the impact of multipliers, it may help jurors arrive at multipliers that better reflect their intended preferences
To show the potential of tools, I've built three interactive prototypes that reveal how rich this design space could be. These tools barely scratch the surface of what's possible.
The design principles guiding these tools:
-
Multiple abstractions unlock coherent preferences. Jurors struggle to express consistent preferences through pairwise comparisons alone. By offering alternative frameworks, we let jurors work with the mental model that best matches their intuition. In these tools we include three alternative frameworks: ranking, weighted voting, and comparison editing.
-
Real-time feedback calibrates judgment. When jurors see immediately how their choices affect funding distributions, they can adjust their inputs to match their actual intentions. A 999x multiplier might feel right until you see it shifts 25% of all funding to one project.
-
Connect local decisions to global outcomes. Every local choice (moving a project up one rank, adjusting one comparison) has global consequences for the entire distribution. By seamlessly switching between viewing individual project comparisons and the full allocation landscape, jurors can understand both the trees and the forest.
The Tools in Action
Deep Funding Allocation Tools
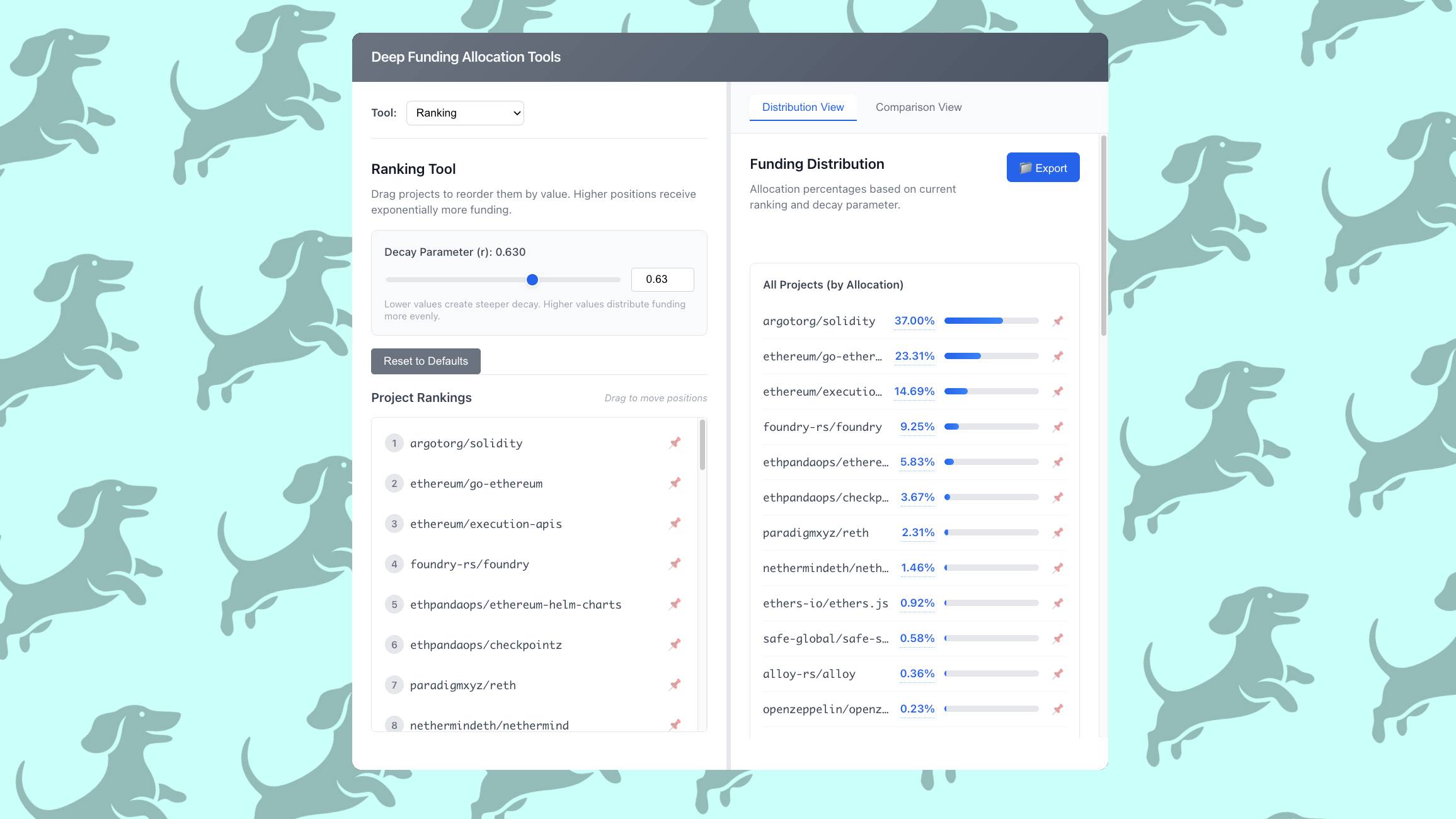
Ranking Tool
Drag projects to reorder them by value. Higher positions receive exponentially more funding.
Project Rankings
Drag to move positionsFunding Distribution
Allocation percentages based on current ranking and decay parameter.
All Projects (by Allocation)
The Ranking Tool
The ranking tool enables a juror to rank the various projects in descending order, then assigns a funding amount to each position using an exponential decay model. The exponential model has a parameter 'r' that can be used to steepen or flatten the weight distribution.
This tool is perfect for jurors who have a clear sense of relative importance but struggle to quantify exact multipliers. Simply drag projects into order, adjust the decay parameter to match your intuition about how steeply value drops off, and see the resulting allocation.
The Voting Tool
The voting tool imagines a world of existing expert ballots available when voting. The juror can select these ballots and then combine them, assigning each expert ballot a weight to contribute towards a final distribution.
Expert ballots might be created by motivated community members who have an agenda around fund allocation. If expert ballots are built around easy-to-understand preferences, such as ranking projects by proven usage, impact surveys, etc., then jurors can mix-and-match expert ballots that suit their preferences. Rather than hiding influence, this tool makes it transparent and manageable.
The Comparisons Tool
The comparisons tool lets a juror add and remove individual project comparisons to a list of comparisons and then calculate the resulting rankings. This can be used to understand the impact of varying a multiplier on the resulting weight distribution. A user can "stress test" their comparison votes before making them, understanding the impact both to the projects being compared but also to other projects based on real data.
For example, take that Juror 17 who rated Solidity 999x over Remix. Using the comparisons tool, that juror could see that their choice of 999x creates a 25% allocation to Solidity under the data present. Armed with that information they might think "Actually, 25% of all Ethereum value seems too high," or they may increase their conviction that the wide disparity between the projects is correct.
What This Means
Deep Funding's core insight remains sound: We can decompose an impossible task into manageable comparisons and then use AI to scale. But the data shows we're asking humans to do something they're fundamentally bad at: expressing consistent quantitative preferences without feedback or framework.
I hope the tools I've built demonstrate that with proper interfaces, jurors could provide more signal with less cognitive burden. But these tools are just explorations. There's much more to learn.
A final thought: In my work on the contest (currently first on the leaderboard!), I've found unexpected value in modeling individual jurors. This suggests jurors aren't imperfect approximations of community consensus but representatives of genuinely different philosophies about value. If true, the challenge isn't getting jurors to agree. It's giving each juror the tools to express their particular philosophy clearly and consistently. If jurors represent fundamentally different philosophies about Ethereum's value, what does that mean for how we should fund its future?